1. Vector
- 특징
: 1차원의 선형 자료구조.
: 변수[index]로 참조 가능. index는 1부터 시작.
: 동일한 자료형만 저장 가능.
- 백터 객체 생성
: 'c()' - 조합, 'seq()' - 수열, 'rep()' - 반복/복제의 함수를 이용하여 생성이 가능하다.
v_num <- c(23, 2:4)
v_char <- c("hoh","kai","moe")
v_log <- c(T,TRUE,FALSE,F)
v_num; v_char; v_log // c++과 같이 세미콜론을 쓰면 한 줄에 여러 statement 작성 가능
// [1] 23 2 3 4
// [1] "hoh" "kai" "moe"
// [1] TRUE TRUE FALSE FALSE
v_seq <- seq(1,20,3) // seq(<시작>,<끝>,<가중치>)
v_seq //[1] 1 4 7 10 13 16 19
v_rep <- rep(1:4,2)
v_rep //[1] 1 2 3 4 1 2 3 4- 백터 자료 처리
: 'union()' - 합집합, 'setdiff()' - 차집합, 'intersect()' - 교집합의 함수를 이용하여 벡터 자료 처리가 가능하다.
x <- c(1,3,5,7)
y <- c(3,5,9)
union(x,y) //[1] 1 3 5 7 9
setdiff(x,y) //[1] 1 7
intersect(x,y) //[1] 3 5
> 자료 처리 우선순위
: 벡터 변수 하나에는 모두 같은 자료형이 들어와야 한다. 숫자, 문자, 논리형 자료들이 같이 있을 때 처리 우선순위를 확인해봤다.
//아까 쓴 v_num, v_char, v_log 변수를 사용했다.
c(v_num,v_char) //[1] "23" "2" "3" "4" "hoh" "kai" "moe"
// - [숫자] < [문자]
c(v_num,v_log) //[1] 23 2 3 4 1 1 0 0
// - [숫자] > [논리] (TRUE는 1, FALSE는 0으로 바뀜)
c(v_log,v_char) //[1] "TRUE" "TRUE" "FALSE" "FALSE" "hoh" "kai" "moe"
// - [논리] < [문자]
c(v_num,v_char,v_log)
//[10] "23" "2" "3" "4" "hoh" "kai" "moe" "TRUE" "TRUE" "FALSE" "FALSE"확인한 결과 문자>숫자>논리 순으로 변환이 된다는 것을 알 수 있었다.(숫자-논리간에는 TRUE가 1, FALSE가 0이 된다.)
> 칼럼(열)명 지정 : 'names()'함수를 이용하여 벡터 데이터에 칼럼명을 지정할 수 있다.
age <- c(30,35,40)
names(age) <- c("kim","Ryu","Lee")
age /*
kim Ryu Lee
30 35 40*/
> 벡터 원소 접근 : 'vec[index]' 형식으로 벡터 원소에 접근할 수 있다. 용례는 다음과 같다.
a <- c(1:10)
a[4:8] //[1] 4 5 6 7 8
a[2:length(a)-1] //[1] 1 2 3 4 5 6 7 8 9
a[2:(length(a)-1)] //[1] 2 3 4 5 6 7 8 9
a[1,2] //Error in a[1, 2] : incorrect number of dimensions
a[c(1,2)] //[1] 1 2
a[-2] //[1] 1 3 4 5 6 7 8 9 10
a[-c(2:7)] //[1] 1 8 9 10여기서 새로 알게 된 점은 '2:length(a)-1'은 2:length(a)의 모든 원소에 -1 연산을 수행한다는 것이다. 따라서 의도에 맞게 쓰려면 괄호'()'를 써서 명확하게 표현할 필요가 있다고 생각한다.
벡터의 원소를 추출하기 위해서는 index를 항상 벡터형으로 입력해야 한다. a[1,2]는 2차원 자료구조에서 좌표를 통해 원소를 추출하는 방법이며 절대 첫 번째, 두 번째 원소를 추출한다는 의미가 아니다. 앞의 예시와 같이 index값을 c(1,2)로 해야만 의도한 대로 추출이 될 수 있다.
'-'를 통해 여집합으로 값을 추출할 수도 있다.
2. Matrix
- 특징
: 2차원 배열형(행렬)의 자료구조.
: 동일한 자료형만 저장 가능.
- Matrix 객체 생성
형식 : matrix(data=NA, nrow=1, ncol=1, byrow=FALSE, dimnames=NULL)
data - 행렬 객체의 대상 자료
nrow/ncol - 행/열의 수 지정
byrow - 행 우선순위 여부 지정
dimnames - 차원 이름 지정
* 위의 형식에서 등호('=') 다음의 값들은 default 값들이다.
* ("byrow = FALSE"의 의미는 행이 아닌 열을 우선으로 데이터를 채운다는 뜻이다.)
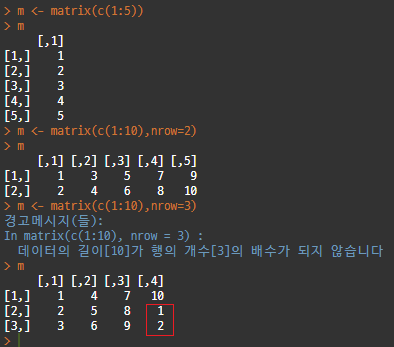
: 행 순서로 데이터를 채우고자 할 때는 'byrow=T' 속성을 추가하면 된다

- 묶음으로 Matrix 객체 생성
: 'rbind()'-행 묶음, 'cbind'-열 묶음 함수를 이용하여 벡터 또는 행렬 값을 묶을 수 있다. 이때 묶고자 하는 행or열의 수가 같아야 한다. (rbind-열의 수, cbind-행의 수)


rbind/cbind 함수의 인자 중 벡터가 포함된 경우에는 행/열의 수가 맞지 않아도 결과가 나오지만 matrix간 조합에는 조건을 만족시켜야만 결과가 나온다.
- 행렬 객체 자료 처리
아래와 같은 방법으로 행렬의 데이터를 추출할 수 있다.

> length(), nrow(), ncol() 함수 : 각각 원소의 개수, 행의 수, 열의 수를 반환한다.

> apply() 함수 : 행렬에 함수를 적용하여 자료를 처리하는데 이용하는 함수.
형식 : 'apply(X, MARGIN, FUN, ....)'
X - 함수를 적용할 행렬 객체
MARGIN - 함수 적용 단위 설정(1=행, 2=열)
FUN - 행렬에 적용할 함수(sum,mean,사용자 정의 함수 등)


행렬 x에 custom_func을 직접 적용하면 [3*3]행렬과 [3*1]행렬(matrix(c(1,2,3)의 결과)의 곱(열 단위 연산)으로 나타내지지만 apply 함수를 이용하면 행 단위로 연산을 할 수 있다.
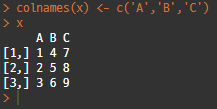
> 행렬에 칼럼명 지정 : 'colnames()' 함수를 이용하여 칼럼명을 지정할 수 있다.
3. Array
- 특징
: 다차원 배열형의 자료구조.
: 상대적으로 활용도가 낮다.

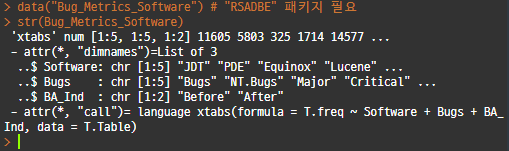
* 'str()' 함수(structure)를 통해 차원의 수와 차원명 등을 알 수 있다.+
4. List
- 특징
: 하나의 메모리에 key와 value가 한 쌍으로 저장된다.
: key를 통해 value를 불러올 수 있으며, value값으로는 vector,matrix,array,list 등의 대부분의 R 자료구조 객체가 저장될 수 있다.
: 함수 내에서 여러 값을 하나의 키로 묶어서 반환하는 경우에 유용하다.
- 1차원 List 객체 생성

[[n]] - key, [n] - value에 해당한다. 위에 코드에서는 키값을 따로 지정하지 않은 경우이다.
아래와 같이 list(<key1>=<value1>, ... ,<key#>=<value#>)의 형식으로 list 객체를 생성할 수 있다.

<listname>$<key>의 형식으로 자료에 접근할 수 있다.

> unlist() : 자료 처리를 편리하게 하기 위해 리스트를 벡터로 변환하여 사용할 수 있게 해 준다.

- List 객체 자료 처리 함수
> 'lapply()'-연산 결과를 list형태로 반환, 'sapply()'-연산 결과를 vector형태로 반환

- 다차원 List 객체 생성
: list의 원소의 value가 list객체로 중첩된 구조를 다차원(중첩) 리스트라고 한다.

위와 같이 다차원 리스트를 do.call() 함수를 통해 리스트를 각각 분해한 후 지정된 함수를 적용하여 효과적으로 처리할 수 있다.
5. Data Frame
- 특징
: R에서 가장 많이 사용하는 자료구조.
: 칼럼 단위로 서로 다른 데이터의 저장이 가능하다.
: 리스트와 벡터의 혼합형으로 칼럼은 리스트, 칼럼 내 데이터는 벡터 자료구조를 갖는다.
- data.frame 객체 생성
형식 : data.frame(<col1>=<data1>,...,<col#>=<data#>) * 칼럼의 data길이가 같지 않으면 Error 발생

read.table(), read.csv() 함수를 통해서도 dataframe을 생성할 수 있다. 이와 관련된 내용은 다음 chapter인 데이터 입출력에서 상세히 다루는 것 같다.
- data.frame 객체 참조
: <변수명>$<칼럼명>형식으로 데이터 참조가 가능하며, 벡터 형식으로 반환된다.

- data.frame 객체 자료 처리 함수
> str() : 데이터프레임 구조를 보여주는 함수.

> summary() : 데이터 통계량(Min,Max,Median,Mean,1Q,3Q)을 요약하여 보여주는 함수.

> matrix에서와 비슷하게 apply 함수를 이용한 자료 처리가 가능하다.

> subset() : 데이터프레임의 부분 객체를 만드는 함수.
형식 : subset(<df 객체>,<조건>). 논리 연산자(AND(&)/OR(|))를 통한 표현이 가능하다.

> merge() : 다수의 데이터프레임을 병합하는 함수.
형식 : merge(<x>,<y>,by.x='<x의 열>',by.y='<y의 열>').
* ?merge를 통해 documentation을 보면 인수들과 옵션이 더 많다.
* by.x의 값과 by.y의 값들 중 둘 모두에게 있는 행만 merge가 된다.

6. 문자열 처리
- strimgr 패키지 : 문자열 연산에 필요한 다양한 함수를 제공해준다.
str_length() : 문자열 길이 반환 / str_c() : 문자열 결합 / str_sub() : 부분 문자열 생성
/ str_split() : 구분자 기준으로 문자열 분리 / str_replace() : 문자열 교체 / str_extract[_all]() : 특정 패턴의 문자열 추출
/ str_locate[_all]() : 특정 패턴의 문자열 위치 찾기
> str_extract 함수
형식 : str_extract(<문자열>,<정규표현식>)

정규표현식 "[0-9]{2}"를 해석하면 숫자([0-9])가 연속 2회{2}로 나타난 문자열 패턴을 의미한다.
* digit의 의미로 '\\d'를 사용할 수도 있다.
비슷한 방법으로 알파벳은[A-z], 한글은[가-힣]으로 이용할 수 있다.
* 알파벳이 대문자 A부터 소문자 z까지인 이유는 ASCII 코드상에서 대문자 A값(65)부터 시작해서인것 같다.

'^'기호를 통해 특정 문자열을 제외한 패턴을 뽑을 수도 있다.

'\\w'는 특수문자를 포함하지 않은 한글,영문자,숫자를 의미한다.

> paste 함수 : 문자열 벡터 객체의 원소를 구분자를 적용하여 하나의 문자열로 합치는 함수.
* data set이 방대할 때 효율적인 처리를 위해 이용한다.

> 그 외의 함수 용례

Chapter 2. 데이터의 유형과 구조 끝.
- Reference
김진성, 『빅데이터 분석을 위한 R프로그래밍』, 가메출판사(2018), p58-90.
'Programming > R' 카테고리의 다른 글
| [R #6] 데이터 조작 (0) | 2020.06.11 |
|---|---|
| [R #5] 데이터 시각화 (0) | 2020.06.06 |
| [R #4] 제어문과 함수 (0) | 2020.06.03 |
| [R #3] 데이터 입출력 (0) | 2020.05.27 |
| [R #1] R 개요 (0) | 2020.05.21 |



댓글