1. 시각화 도구 분류
> 변수의 연속성에 따른 분류
| 이산변수 | 연속변수 |
| 막대, 점, 원형차트 등 | 상자 박스, 히스토그램, 산점도 등 |
> 칼럼 특성에 따른 분류
| 칼럼 특성 | 도구 | |
| 숫자형 | 범주형 | |
| 1 | hist, plot, barplot | |
| 1 | pie, barplot | |
| 2 | plot, abline, boxplot | |
| 3 | scatterplot3d | |
| n | n | pairs |
2. 이산변수 시각화
> 막대 차트 시각화(barplot)
| argument | 내용 |
| xlim/ylim | x/y 축 값 범위 |
| xlab/ylab | x/y 축 이름 |
| col | 색상 |
| main | 차트 제목 |
| hoirz | 가로 막대형 설정(default = F) |
| beside | x축 값을 측면으로 배열(F = 누적 막대) |
| space | 막대 간격(커질수록 막대 굵기는 작아짐) |
| cex | 막대 크기 설정(character expansion) |
대부분의 argument는 다른 차트 함수에서도 똑같이 사용이 가능하다. 이 외에도 엄청 많다.

par(mfrow=c())를 이용하여 한 영역에 여러 차트를 배치할 수 있다. 또한 legend() 함수는 특정 위치에 범례를 표시한다.
> 점 차트 시각화(dotchart)

- lcolor : 구분선 색상
- pch(plotting character) : 점 모양
> 원형 차트 시각화(pie)

- lables : 레이블 표시(보통 colname이나 데이터값 이용)
3. 연속변수 시각화
> 상자 그래프 시각화(boxplot) : 데이터의 분포 정도, 이상치 발견에 유용
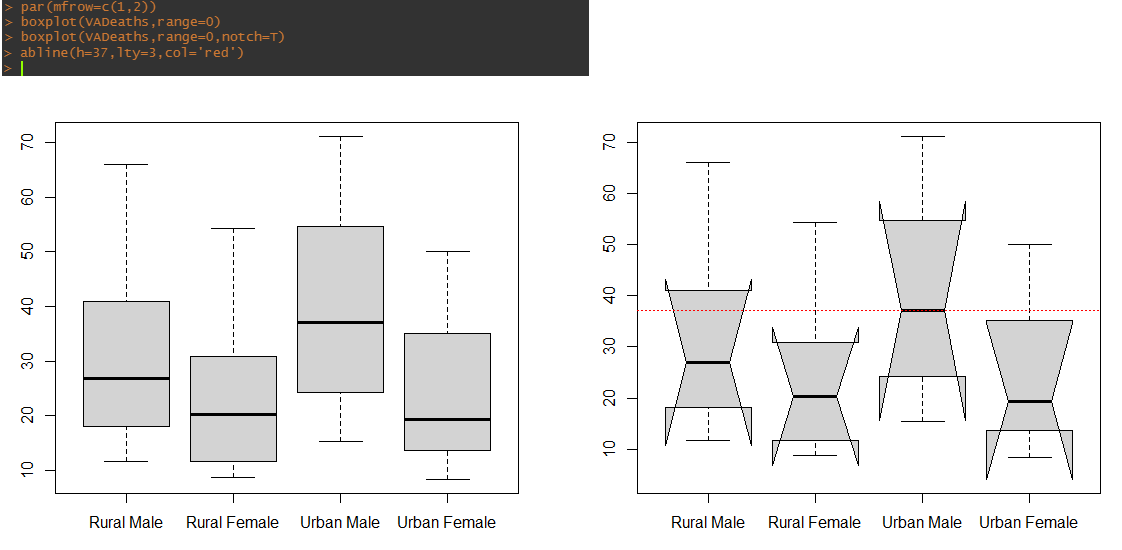
- range : 최소/최대값 연결 방식
- notch : 중앙값에 대한 신뢰구간(오목한 부분)
- abline(위치,선 스타일) : 차트에서 기준선을 추가하는 함수
> 히스토그램 시각화(hist)

- freq : 도수 표현 여부(default = T, 값이 F이면 밀도로 표현)
- lines : 데이터에 대한 분포 곡선을 그리는 함수
> 정규분포 곡선 추정
: 정규성 검정의 한 방법. 데이터의 정규성 여부는 분석 방법을 정하는데 중요한 요소이다.

* Sepal width의 밀도분포 곡선과 해당 데이터의 평균과 표준편차를 가지는 정규분포 곡선의 추세가 유사하다. 따라서 iris 데이터 셋의 Sepal width는 정규분포를 따른다고 볼 수 있다.
> 산점도 시각화(plot) : 두 변수의 관계를 시각적으로 분석할 때 유용하다.

- ann : 축 제목 표시여부(위의 코드에서는 기존 차트에 line만 추가하므로 축을 빼버린다.)
- axes : 축 표시 여부
- text : 차트에 텍스트 추가
- type : 표현 방식설정(default = p)
- pch : 연결점 스타일(style character)


> 중첩 자료 시각화 : 동일한 값을 가지는 데이터가 여러개일 경우 처리 하는 방법.

* cex특성의 값을 빈도수에 비례하게 설정하여 위와 같이 시각화를 할 수 있다.
> 변수간 비교 시각화(pairs, scatterplot3d)
- pairs

- scatterplot3d


데이터 시각화와 관련한 부분은 정말 다양한 요소들이 많고, 프로그래머의 성향에 따라 표현 방식이 달라질 수 있기 때문에 경험치가 가장 큰 요소로 작용할 것 같은 내용들이라고 생각된다. 그래서 이번 단원에서는 부가 설명을 하기엔 배경 지식도 부족하고 경험도 없다보니 책에 나온 과정들을 그대로 옮긴 수준이 된 것 같다.
Chapter 5. 데이터 시각화 끝.
- Reference
김진성, 『빅데이터 분석을 위한 R프로그래밍』, 가메출판사(2018), p140-169.
'Programming > R' 카테고리의 다른 글
| [R #6] 데이터 조작 (0) | 2020.06.11 |
|---|---|
| [R #4] 제어문과 함수 (0) | 2020.06.03 |
| [R #3] 데이터 입출력 (0) | 2020.05.27 |
| [R #2] 데이터의 유형과 구조 (0) | 2020.05.24 |
| [R #1] R 개요 (0) | 2020.05.21 |




댓글